import torch
# Creates a 2x3 uninitialized FloatTensor
tensor = torch.Tensor(2, 3)
print(tensor)tensor([[-2.8516e+14, 4.0537e-41, 1.0344e-14],
[ 0.0000e+00, 4.4842e-44, 0.0000e+00]])collate_fn
import torch
# Creates a 2x3 uninitialized FloatTensor
tensor = torch.Tensor(2, 3)
print(tensor)tensor([[-2.8516e+14, 4.0537e-41, 1.0344e-14],
[ 0.0000e+00, 4.4842e-44, 0.0000e+00]])import torch
# Creates a tensor with specific values
data = [[1, 2], [3, 4]]
tensor = torch.tensor(data, dtype=torch.float32)
print(tensor)tensor([[1., 2.],
[3., 4.]])
# Define tensors
a = torch.tensor([1, 2, 3]) # Shape: (3,)
b = torch.tensor([4, 5]) # Shape: (2,)
try:
result_direct = a * b
except RuntimeError as e:
print("Error without reshaping:\n", e)
# Output:
# RuntimeError: The size of tensor a (3) must match the size of tensor b (2) at non-singleton dimension 0
# Reshape tensors for broadcasting
a_reshaped = a.view(3, 1) # Shape: (3, 1)
b_reshaped = b.view(1, 2) # Shape: (1, 2)
# Multiply after reshaping
result_broadcast = a_reshaped * b_reshaped
print("Result after reshaping and multiplying:\n", result_broadcast)
# Output:Error without reshaping:
The size of tensor a (3) must match the size of tensor b (2) at non-singleton dimension 0
Result after reshaping and multiplying:
tensor([[ 4, 5],
[ 8, 10],
[12, 15]])import torch
def matmul(a,b): return torch.einsum('ik,kj->ij',a,b)
m1 = torch.randn(5,28*28)
m2 = torch.randn(784, 10)
%timeit -n 10 t5 = matmul(m1,m2)The slowest run took 130.41 times longer than the fastest. This could mean that an intermediate result is being cached.
164 μs ± 380 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)def batch_matmul(a, b):
return torch.einsum('bik,bkj->bij', a, b)
# Example usage
batch_size = 2
i, k, j = 3, 4, 5
a = torch.randn(batch_size, i, k)
b = torch.randn(batch_size, k, j)
result = batch_matmul(a, b)
print("Batch MatMul Result Shape:", result.shape)Batch MatMul Result Shape: torch.Size([2, 3, 5])def outer_product(a,b):
return torch.einsum('i,j->ij',a,b)
a = torch.tensor([1, 2, 3]) # shape (3,) -> (3,1)
b = torch.tensor([4, 5]) # shape (2,) -> (1.2)
result = outer_product(a, b)
print("Outer Product Result:\n", result)Outer Product Result:
tensor([[ 4, 5],
[ 8, 10],
[12, 15]])def dot_product(a, b):
return torch.einsum('i,i->', a, b)
# Define tensors
a = torch.tensor([1, 2, 3]) # Shape: (3,)
b = torch.tensor([4, 5, 6]) # Shape: (3,)
# Compute dot product using einsum
result = dot_product(a, b)
print("Dot Product Result:", result)Dot Product Result: tensor(32)def transpose(a):
return torch.einsum('ij->ji', a)
# Example usage
a = torch.tensor([[1, 2, 3], [4, 5, 6]])
result = transpose(a)
print("Transpose Result:\n", result)Transpose Result:
tensor([[1, 4],
[2, 5],
[3, 6]])def sum_over_dim(a):
return torch.einsum('ij->i', a)
# Example usage
a = torch.tensor([[1, 2, 3], [4, 5, 6]])
result = sum_over_dim(a)
print("Sum Over Rows:", result)
# Output: Sum Over Rows: tensor([ 6, 15])Sum Over Rows: tensor([ 6, 15])def attention_scores(query, key):
return torch.einsum('bqd,bkd->bqk', query, key) # sum the products across the feature dimension d to compute attention scores
# Example usage
batch_size, q, d, k = 2, 3, 4, 4
query = torch.randn(batch_size, q, d)
key = torch.randn(batch_size, k, d)
scores = attention_scores(query, key)
print(query)
print(key)
print(scores)
print("Attention Scores Shape:", scores.shape)
# Output: Attention Scores Shape: torch.Size([2, 3, 4])tensor([[[ 1.9826, 0.6645, -0.9895, -0.0247],
[-1.5472, 0.6203, -0.9500, -0.3087],
[ 0.3845, 0.3481, 0.2347, 0.7434]],
[[ 1.0612, 1.7969, -0.4906, -0.1500],
[-0.3895, 1.5363, -0.4685, -0.4239],
[ 0.9783, -0.3329, 0.9564, 0.3776]]])
tensor([[[-1.5022, 1.1593, 0.8890, 1.0148],
[ 1.1577, 0.4848, -0.1506, 1.7842],
[-1.4799, 0.6236, 0.7959, 0.1494],
[-1.7694, -1.7675, 0.2545, 0.0117]],
[[-1.1997, 1.1282, -0.8853, -0.8205],
[-0.4073, -1.8880, 0.1635, 0.8772],
[ 0.2545, -1.0884, -0.1758, -0.2735],
[-0.1619, 1.4902, 0.2765, -1.1585]]])
tensor([[[-3.1126, 2.7223, -3.3110, -4.9348],
[ 1.8854, -1.8981, 1.8743, 1.3959],
[ 0.7889, 1.9051, -0.0542, -1.2273]],
[[ 1.3114, -4.0365, -1.5585, 2.5441],
[ 2.9630, -3.1904, -1.5730, 2.7140],
[-2.7057, 0.7177, 0.3398, -0.8274]]])
Attention Scores Shape: torch.Size([2, 3, 4])import numpy as np
np.dot([ 1.9826, 0.6645, -0.9895, -0.0247],[-1.5022, 1.1593, 0.8890, 1.0148])-3.11263793np.dot([ 1.9826, 0.6645, -0.9895, -0.0247],[ 1.1577, 0.4848, -0.1506, 1.7842])2.7223545799999997def weighted_sum(attention_weights, value):
return torch.einsum('bqk,bvd->bqd', attention_weights, value)
# Example usage
batch_size, q, k, d = 2, 3, 4, 5
attention_weights = torch.randn(batch_size, q, k) # (2,3,4)
value = torch.randn(batch_size, d, 5) # (2,5,5)
result = weighted_sum(attention_weights, value)
print("Weighted Sum Result Shape:", result.shape)
# Output: Weighted Sum Result Shape: torch.Size([2, 3, 5])def outer_product(a, b):
return torch.einsum('i,j->ij', a, b)
# Example usage
a = torch.tensor([1, 2, 3])
b = torch.tensor([4, 5, 6])
result = outer_product(a, b)
print("Outer Product Result:\n", result)
# Output:
# Outer Product Result:
# tensor([[ 4, 5, 6],
# [ 8, 10, 12],
# [12, 15, 18]])__init__(),__len__(), and __getitem__() methods to be used by the data loader.import torch
torch.manual_seed(42)
t_x = torch.rand([4,3],dtype = torch.float32)
t_y = torch.arange(4)
from torch.utils.data import Dataset, DataLoader
class JointDataset(Dataset):
def __init__(self,x,y):
self.x = x
self.y = y
def __len__(self):
return len(self.x)
def __getitem__(self, index):
return self.x[index], self.y[index]
joint_dataset = JointDataset(t_x,t_y)
# alternatively, can create a joint dataset using TensorDataset
# from torch.utils.data import TensorDataset
# tensor_dataset = JointDataset(t_x,t_y)
data_loader = DataLoader(dataset=joint_dataset,batch_size=2,shuffle=True) # will shuffle for every epoch!import torch
from torch.utils.data import Dataset, DataLoader
seq_len = 40
chunk_size = seq_len +1
text_chunks = [text_encoded[i:i+chunk_size] for i in range(len(text_encoded)-chunk_size+1)]
class TextDataset(Dataset):
def __init__(self, text_chunks):
self.text_chunks = text_chunks
def __len__(self):
return len(self.text_chunks)
def __getitem__(self, index):
text_chunk = self.text_chunks[index]
return text_chunks[:-1].long(), text_chunks[1:].long()
seq_dataset = TextDataset(torch.tensor(text_chunks))
seq_dl = DataLoader(seq_dataset,batch_size=batch_size, shuffle=True, drop_last=True)collate_fnimport warnings
warnings.filterwarnings("ignore", category=FutureWarning, module="huggingface_hub")
import torch
from torch.utils.data import DataLoader, Dataset
from transformers import BertTokenizer
from torch.nn.utils.rnn import pad_sequence
PAD_TOKEN = 0
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
class LanguageModelingDataset(Dataset):
def __init__(self, texts, tokenizer, max_length=512):
"""
Args:
texts (List[str]): List of text samples.
tokenizer (transformers.PreTrainedTokenizer): Tokenizer for encoding text.
max_length (int): Maximum sequence length.
"""
self.tokenizer = tokenizer
self.max_length = max_length
self.encodings = self.tokenizer(texts, truncation=True, padding=False) # No padding here
def __len__(self):
return len(self.encodings['input_ids'])
def __getitem__(self, idx):
return torch.tensor(self.encodings['input_ids'][idx], dtype=torch.long)
def custom_collate_fn(batch):
# Same as before
input_sequences = [sample[:-1] for sample in batch]
target_sequences = [sample[1:] for sample in batch]
padded_inputs = pad_sequence(input_sequences, batch_first=True, padding_value=PAD_TOKEN)
padded_targets = pad_sequence(target_sequences, batch_first=True, padding_value=PAD_TOKEN)
attention_masks = (padded_inputs != PAD_TOKEN).long()
return padded_inputs, padded_targets, attention_masks
# Example texts
texts = [
"Hello, how are you?",
"I am fine, thank you!",
"What are you doing today?",
"I am working on a language model."
]
# Create Dataset and DataLoader
dataset = LanguageModelingDataset(texts, tokenizer)
dataloader = DataLoader(dataset, batch_size=2, collate_fn=custom_collate_fn, shuffle=True)
# Iterate through DataLoader
for batch_idx, (inputs, targets, masks) in enumerate(dataloader):
print(f"Batch {batch_idx + 1}")
print("Inputs:\n", inputs)
print("Targets:\n", targets)
print("Attention Masks:\n", masks)
print("-" * 50)Batch 1
Inputs:
tensor([[ 101, 2054, 2024, 2017, 2725, 2651, 1029, 0, 0],
[ 101, 1045, 2572, 2551, 2006, 1037, 2653, 2944, 1012]])
Targets:
tensor([[2054, 2024, 2017, 2725, 2651, 1029, 102, 0, 0],
[1045, 2572, 2551, 2006, 1037, 2653, 2944, 1012, 102]])
Attention Masks:
tensor([[1, 1, 1, 1, 1, 1, 1, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1]])
--------------------------------------------------
Batch 2
Inputs:
tensor([[ 101, 7592, 1010, 2129, 2024, 2017, 1029, 0],
[ 101, 1045, 2572, 2986, 1010, 4067, 2017, 999]])
Targets:
tensor([[7592, 1010, 2129, 2024, 2017, 1029, 102, 0],
[1045, 2572, 2986, 1010, 4067, 2017, 999, 102]])
Attention Masks:
tensor([[1, 1, 1, 1, 1, 1, 1, 0],
[1, 1, 1, 1, 1, 1, 1, 1]])
--------------------------------------------------import torch.nn as nn
class NoisyLinear(nn.Module):
def __init__(self,input_size,output_size,noise_stddev=0.1):
super().__init__()
w = torch.Tensor(input_size, output_size)
self.w = nn.Parameter(w) # will be included in model.parameters() passed to the optimizer
nn.init.xavier_uniform_(self.w)
b = torch.Tensor(output_size).fill_(0)
self.b = nn.Parameter(b)
self.noise_stddev = noise_stddev
def forward(self,x,training=False):
if training:
noise = torch.normal(0.0, self.noise_stddev, x.shape)
x_new = torch.add(x,noise)
else:
x_new = x
return torch.add(torch.mm(x_new,self.w),self.b)
class NoisyModule(nn.Module):
def __init_(self):
super().__init__()
self.l1 = NoisyLinear(2,4,0.07)
self.a1 = nn.ReLU()
...
def forward(self,x,training=False):
x = self.l1(x,training)
x = self.a1(x)
...
def predict(self,x):
x = torch.tensor(x,dtype=torch.float32)
pred = self.forward(x)[:,0] # tra
return (pred>=0.5).float()
# inside the training loop, use training = True
...
pred = model(x_batch,training=True)[:,0]torch.nn.functionalimport torch
def custom_mse_loss(y_pred, y_true):
return torch.mean((y_pred - y_true) ** 2)
y_true = torch.tensor([1.0, 2.0, 3.0])
y_pred = torch.tensor([1.5, 2.5, 3.5])
loss = custom_mse_loss(y_pred, y_true)
print(loss) # Output: 0.25tensor(0.2500)nn.Module, as in the following ElasticNet example:import torch
import torch.nn as nn
class ElasticNetLoss(nn.Module):
def __init__(self, alpha=1.0, beta=1.0):
super().__init__()
self.alpha = alpha # Weight for L1 loss
self.beta = beta # Weight for L2 loss
def forward(self, y_pred, y_true):
l1_loss = torch.sum(torch.abs(y_pred - y_true))
l2_loss = torch.sum((y_pred - y_true) ** 2)
return self.alpha * l1_loss + self.beta * l2_loss
loss_fn = ElasticNetLoss(alpha=0.5, beta=0.5)
y_true = torch.tensor([1.0, 2.0, 3.0])
y_pred = torch.tensor([1.5, 2.5, 3.5])
loss = loss_fn(y_pred, y_true)
print(loss) # Output: Weighted combination of L1 and L2 lossestensor(1.1250)import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms, models
from torch.utils.data import DataLoader
import time
import copy
# 1. Define device
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 2. Data transformations
data_transforms = {
'train': transforms.Compose([
transforms.Resize(256),
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
]),
}
# 3. Load datasets
data_dir = './data/CIFAR10'
image_datasets = {
'train': datasets.CIFAR10(root=data_dir, train=True,
download=True, transform=data_transforms['train']),
'val': datasets.CIFAR10(root=data_dir, train=False,
download=True, transform=data_transforms['val'])
}
dataloaders = {
'train': DataLoader(image_datasets['train'], batch_size=32,
shuffle=True, num_workers=4),
'val': DataLoader(image_datasets['val'], batch_size=32,
shuffle=False, num_workers=4)
}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes
print(f"Classes: {class_names}")
print(f"Training samples: {dataset_sizes['train']}")
print(f"Validation samples: {dataset_sizes['val']}")
# 4. Initialize model
model_ft = models.resnet50(pretrained=True)
# Freeze all layers
for param in model_ft.parameters():
param.requires_grad = False
# Modify final layer
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, len(class_names)) # 10 classes for CIFAR-10
model_ft = model_ft.to(device)
print(model_ft)
# 5. Define loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer_ft = optim.AdamW(model_ft.fc.parameters())
# 6. Training function
def train_model(model, criterion, optimizer, dataloaders, device, num_epochs=10):
since = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print(f'Epoch {epoch+1}/{num_epochs}')
print('-' * 10)
# Training and validation phases
for phase in ['train', 'val']:
if phase == 'train':
model.train()
else:
model.eval()
running_loss = 0.0
running_corrects = 0
# Iterate over data
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
# Forward
with torch.set_grad_enabled(phase == 'train'): #more general case of torch.no_grad that takes a bool to enable/disable grad!
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# Backward + optimize
if phase == 'train':
loss.backward()
optimizer.step()
# Statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print(f'{phase.capitalize()} Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f}')
# Deep copy
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
print()
time_elapsed = time.time() - since
print(f'Training completed in {int(time_elapsed // 60)}m {int(time_elapsed % 60)}s')
print(f'Best Validation Accuracy: {best_acc:.4f}')
# Load best model weights
model.load_state_dict(best_model_wts)
return model
# 7. Train the model
trained_model = train_model(model_ft, criterion, optimizer_ft,
dataloaders, device, num_epochs=10)
# 8. Save the model
model_path = './resnet50_cifar10.pth'
torch.save(trained_model.state_dict(), model_path)
print(f'Model saved to {model_path}')
# 9. Evaluate the model
model_loaded = models.resnet50(pretrained=False)
num_ftrs = model_loaded.fc.in_features
model_loaded.fc = nn.Linear(num_ftrs, len(class_names))
model_loaded.load_state_dict(torch.load(model_path))
model_loaded = model_loaded.to(device)
model_loaded.eval()
def evaluate_model(model, dataloader, device):
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in dataloader['val']:
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
total += labels.size(0)
correct += (preds == labels).sum().item()
print(f'Validation Accuracy: {100 * correct / total:.2f}%')
evaluate_model(model_loaded, dataloaders, device)Files already downloaded and verified
Files already downloaded and verified
Classes: ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
Training samples: 50000
Validation samples: 10000/home/mainuser/anaconda3/envs/mintonano/lib/python3.11/site-packages/torchvision/models/_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.
warnings.warn(
/home/mainuser/anaconda3/envs/mintonano/lib/python3.11/site-packages/torchvision/models/_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=ResNet50_Weights.IMAGENET1K_V1`. You can also use `weights=ResNet50_Weights.DEFAULT` to get the most up-to-date weights.
warnings.warn(msg)ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer2): Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer3): Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer4): Sequential(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=2048, out_features=10, bias=True)
)
Epoch 1/10
----------
Train Loss: 1.2826 Acc: 0.5558
Val Loss: 0.8192 Acc: 0.7177
Epoch 2/10
----------
Train Loss: 1.1801 Acc: 0.5877
Val Loss: 0.7847 Acc: 0.7259
Epoch 3/10
----------
Train Loss: 1.1608 Acc: 0.5998
Val Loss: 0.8015 Acc: 0.7259
Epoch 4/10
----------
Train Loss: 1.1382 Acc: 0.6043
Val Loss: 0.7306 Acc: 0.7492
Epoch 5/10
----------
Train Loss: 1.1179 Acc: 0.6120
Val Loss: 0.7977 Acc: 0.7242
Epoch 6/10
----------
Train Loss: 1.1129 Acc: 0.6133
Val Loss: 0.8184 Acc: 0.7138
Epoch 7/10
----------
Train Loss: 1.1162 Acc: 0.6126
Val Loss: 0.7187 Acc: 0.7475
Epoch 8/10
----------
Train Loss: 1.1082 Acc: 0.6165
Val Loss: 0.7185 Acc: 0.7482
Epoch 9/10
----------
Train Loss: 1.0961 Acc: 0.6205
Val Loss: 0.7538 Acc: 0.7399
Epoch 10/10
----------
Train Loss: 1.0969 Acc: 0.6188
Val Loss: 0.7467 Acc: 0.7422
Training completed in 9m 9s
Best Validation Accuracy: 0.7492
Model saved to ./resnet50_cifar10.pth/home/mainuser/anaconda3/envs/mintonano/lib/python3.11/site-packages/torchvision/models/_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=None`.
warnings.warn(msg)
/tmp/ipykernel_554687/107893568.py:148: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
model_loaded.load_state_dict(torch.load(model_path))Validation Accuracy: 74.92%import torch
num_epochs = 10
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-5)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=num_epochs)
for epoch in range(num_epochs):
for input, target in dataset:
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
scheduler.step()T_max: This parameter defines the maximum number of iterations (typically epochs) for one cycle of the cosine annealing schedule. Essentially, it determines the period over which the learning rate decreases from the initial value down to the minimum learning rate (eta_min).
Single-Cycle Annealing: If you set T_max equal to the total number of training epochs, the learning rate will smoothly decrease from the initial learning rate to eta_min over the entire training process.
Multi-Cycle Annealing: By setting T_max to a fraction of the total epochs, you can create multiple cycles of learning rate adjustments within the training process. For more advanced multi-cycle schedules, consider using CosineAnnealingWarmRestarts.
torch.save(model, PATH_TO_MODEL) # example path: "model.pth"
model = torch.load(PATH_TO_MODEL)torch.save(model.state_dict(),PATH_TO_MODEL)
model = ConvNet()
model.load_state_dict(torch.load(PATH_TO_MODEL))
model.eval()torch.save() with a dictionary containing these components.torch.load() to retrieve the saved state.import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import os
# --------- 1. Define the Neural Network ---------
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.flatten = nn.Flatten()
self.fc1 = nn.Linear(28 * 28, 128) # MNIST images are 28x28
self.relu = nn.ReLU()
self.fc2 = nn.Linear(128, 10) # 10 output classes
def forward(self, x):
x = self.flatten(x)
x = self.relu(self.fc1(x))
x = self.fc2(x)
return x
# --------- 2. Prepare Data ---------
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)) # Normalize with MNIST mean and std
])
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
val_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=1000, shuffle=False)
# --------- 3. Initialize Model, Criterion, Optimizer ---------
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = SimpleNN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# --------- 4. Define Checkpoint Saving Function ---------
def save_checkpoint(state, filename='best_model.pth'):
"""
Saves the training state.
Args:
state (dict): Contains model state_dict, optimizer state_dict, epoch, best_acc, etc.
filename (str): Path to save the checkpoint.
"""
torch.save(state, filename)
print(f'Checkpoint saved to {filename}')
# --------- 5. Define Checkpoint Loading Function ---------
def load_checkpoint(filename, model, optimizer):
"""
Loads the training state.
Args:
filename (str): Path to the checkpoint.
model (nn.Module): Model to load the state_dict into.
optimizer (torch.optim.Optimizer): Optimizer to load the state_dict into.
Returns:
int: The epoch to resume training from.
float: The best validation accuracy so far.
"""
if os.path.isfile(filename):
print(f"Loading checkpoint '{filename}'")
checkpoint = torch.load(filename)
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
best_acc = checkpoint['best_acc']
print(f"Loaded checkpoint '{filename}' (epoch {epoch}) with best accuracy {best_acc:.2f}%)")
return epoch, best_acc
else:
print(f"No checkpoint found at '{filename}'")
return 0, 0.0
# --------- 6. Define Training and Validation Functions ---------
def train(model, device, train_loader, optimizer, criterion, epoch):
model.train() # Set model to training mode
running_loss = 0.0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad() # Zero the gradients
output = model(data) # Forward pass
loss = criterion(output, target) # Compute loss
loss.backward() # Backward pass
optimizer.step() # Update parameters
running_loss += loss.item()
if batch_idx % 100 == 99: # Print every 100 batches
print(f'Epoch {epoch} [{batch_idx +1}/{len(train_loader)}] - Loss: {running_loss / 100:.4f}')
running_loss = 0.0
def validate(model, device, val_loader, criterion):
model.eval() # Set model to evaluation mode
val_loss = 0.0
correct = 0
with torch.no_grad(): # Disable gradient computation
for data, target in val_loader:
data, target = data.to(device), target.to(device)
output = model(data)
val_loss += criterion(output, target).item() # Sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # Get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
val_loss /= len(val_loader.dataset)
accuracy = 100. * correct / len(val_loader.dataset)
print(f'\nValidation set: Average loss: {val_loss:.4f}, Accuracy: {correct}/{len(val_loader.dataset)} ({accuracy:.2f}%)\n')
return val_loss, accuracy
# --------- 7. Main Training Loop with Checkpointing ---------
num_epochs = 5
checkpoint_path = 'best_model.pth'
start_epoch = 1
best_accuracy = 0.0
# Load checkpoint if exists
if os.path.isfile(checkpoint_path):
start_epoch, best_accuracy = load_checkpoint(checkpoint_path, model, optimizer)
start_epoch += 1 # Start from next epoch
else:
print("No checkpoint found. Starting training from scratch.")
for epoch in range(start_epoch, num_epochs +1):
train(model, device, train_loader, optimizer, criterion, epoch)
val_loss, val_accuracy = validate(model, device, val_loader, criterion)
# Check if current accuracy is better than best_accuracy
if val_accuracy > best_accuracy:
best_accuracy = val_accuracy
checkpoint = {
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'best_acc': best_accuracy,
}
save_checkpoint(checkpoint, checkpoint_path)# server.py
import os
import json
import numpy as np
from flask import Flask, request
import torch
import torch.nn as nn
import torch.nn.functional as F
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet, self).__init__()
self.cn1 = nn.Conv2d(1, 16, 3, 1)
self.cn2 = nn.Conv2d(16, 32, 3, 1)
self.dp1 = nn.Dropout2d(0.10)
self.dp2 = nn.Dropout2d(0.25)
self.fc1 = nn.Linear(4608, 64) # 4608 is basically 12 X 12 X 32
self.fc2 = nn.Linear(64, 10)
def forward(self, x):
x = self.cn1(x)
x = F.relu(x)
x = self.cn2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dp1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dp2(x)
x = self.fc2(x)
op = F.log_softmax(x, dim=1)
return op
model = ConvNet()
PATH_TO_MODEL = "./convnet.pth"
model.load_state_dict(torch.load(PATH_TO_MODEL, map_location="cpu"))
model.eval()
def run_model(input_tensor):
model_input = input_tensor.unsqueeze(0)
with torch.no_grad():
model_output = model(model_input)[0]
model_prediction = model_output.detach().numpy().argmax()
return model_prediction
def post_process(output):
return str(output)
app = Flask(__name__)
@app.route("/test", methods=["POST"])
def test():
# 1. Preprocess
data = request.files['data'].read()
md = json.load(request.files['metadata'])
input_array = np.frombuffer(data, dtype=np.float32)
input_image_tensor = torch.from_numpy(input_array).view(md["dims"])
# 2. Inference
output = run_model(input_image_tensor)
# 3. Postprocess
final_output = post_process(output)
return final_output
if __name__ == '__main__':
app.run(host='0.0.0.0', port=8890)# make_request.py
import io
import json
import requests
from PIL import Image
from torchvision import transforms
image = Image.open("./digit_image.jpg")
def image_to_tensor(image):
gray_image = transforms.functional.to_grayscale(image)
resized_image = transforms.functional.resize(gray_image, (28, 28))
input_image_tensor = transforms.functional.to_tensor(resized_image)
input_image_tensor_norm = transforms.functional.normalize(input_image_tensor, (0.1302,), (0.3069,))
return input_image_tensor_norm
image_tensor = image_to_tensor(image)
dimensions = io.StringIO(json.dumps({'dims': list(image_tensor.shape)}))
data = io.BytesIO(bytearray(image_tensor.numpy()))
r = requests.post('http://localhost:8890/test',
files={'metadata': dimensions, 'data' : data})
response = json.loads(r.content)
print("Predicted digit :", response)FROM python:3.9-slim
RUN apt-get -q update && apt-get -q install -y wget
COPY ./server.py ./
COPY ./requirements.txt ./
RUN wget -q https://github.com/PacktPublishing/Mastering-PyTorch/raw/master/Chapter10/convnet.pth
RUN wget -q https://github.com/PacktPublishing/Mastering-PyTorch/raw/master/Chapter10/digit_image.jpg
RUN pip install -r requirements.txt
USER root
ENTRYPOINT ["python", "server.py"]docker build -t digit_recognizer .
docker run -p 8890:8890 digit_recognizer# Step 1: Define and instantiate the model
import torch
import torch.nn as nn
import torch.nn.functional as F
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet, self).__init__()
self.cn1 = nn.Conv2d(1, 16, 3, 1)
self.cn2 = nn.Conv2d(16, 32, 3, 1)
self.dp1 = nn.Dropout2d(0.10)
self.dp2 = nn.Dropout2d(0.25)
self.fc1 = nn.Linear(4608, 64) # 4608 is basically 12 X 12 X 32
self.fc2 = nn.Linear(64, 10)
def forward(self, x):
x = self.cn1(x)
x = F.relu(x)
x = self.cn2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dp1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dp2(x)
x = self.fc2(x)
op = F.log_softmax(x, dim=1)
return op
model = ConvNet()
# Step 2: Load the model's state_dict and put model in eval mode
PATH_TO_MODEL = "./convnet.pth"
model.load_state_dict(torch.load(PATH_TO_MODEL, map_location="cpu"))
model.eval()
# Step 3: Turn off gradient tracking unless already loaded the model with torch.no_grad
for p in model.parameters(): p.requires_grad_(False)
# Step 4: Trace the model
demo_input = torch.ones(1, 1, 28, 28)
traced_model = torch.jit.trace(model, demo_input)
print(traced_model.graph)
print(traced_model.code)
# Step 5: Save the traced model
torch.jit.save(traced_model, 'traced_convnet.pt')
# Step 6: Load the model and use it for inference on a preprocessed image
loaded_traced_model = torch.jit.load('traced_convnet.pt')
image = Image.open("./digit_image.jpg")
def image_to_tensor(image):
...
return input_image_tensor_norm
input_tensor = image_to_tensor(image)
loaded_traced_model(input_tensor.unsqueeze(0))
# Should produce the same output as
model(input_tensor.unsqueeze(0))torch.jit.script instead of torch.jit.trace.scripted_model = torch.jit.script(model)
import tensorflow as tf
import onnx2tf
# As with tracing, pass dummy input through the model as you export it to onnx
demo_input = torch.ones(1, 1, 28, 28)
torch.onnx.export(model, demo_input, "convnet.onnx")
# Next load it and convert it to TensorFlow
onnx2tf.convert(input_onnx_file_path="convnet.onnx",
output_folder_path="convnet_tf",
non_verbose=True)
model = tf.saved_model.load("./convnet_tf/")
print(model)
#<ConcreteFunction (inputs_0: TensorSpec(shape=(1, 28, 28, 1), dtype=tf.float32, name='inputs_0')) -> TensorSpec(shape=(1, 10), dtype=tf.float32, name='unknown'
output = model(input_tensor.unsqueeze(-1))
print(output) # should match the output from the original PyTorch modelimport logging
from transformers import BertForSequenceClassification, BertTokenizer
import torch
from ts.torch_handler.base_handler import BaseHandler
# Configure logging
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
handler = logging.StreamHandler()
formatter = logging.Formatter('[%(asctime)s] %(levelname)s - %(message)s')
handler.setFormatter(formatter)
logger.addHandler(handler)
class TransformersHandler(BaseHandler):
def initialize(self, ctx):
logger.info("Initializing the TransformersHandler.")
self.manifest = ctx.manifest
properties = ctx.system_properties
model_dir = properties.get("model_dir")
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
logger.info(f"Using device: {self.device}")
self.model = BertForSequenceClassification.from_pretrained(model_dir)
self.tokenizer = BertTokenizer.from_pretrained(model_dir)
self.model.to(self.device)
self.model.eval()
logger.info("Model and tokenizer loaded successfully.")
def preprocess(self, data):
logger.info("Preprocessing input data.")
logger.debug(f"Raw data received: {data}")
logger.info(f"DATA: {data}")
data_body = data[0]['body'] # should have probably figured out I needed to access this pre-Docker!
logger.info(f"DATA_BODY: {data_body}")
text = data_body.get("text")
if isinstance(text, bytes):
text = text.decode('utf-8')
logger.debug(f"Decoded text: {text}")
try:
inputs = self.tokenizer(
text,
return_tensors="pt",
truncation=True,
padding=True
)
logger.debug(f"Tokenized inputs: {inputs}")
except Exception as e:
logger.error(f"Error during tokenization: {e}")
raise e
return inputs
def inference(self, inputs):
logger.info("Performing inference.")
try:
with torch.no_grad():
inputs = {k: v.to(self.device) for k, v in inputs.items()}
outputs = self.model(**inputs)
probs = torch.nn.functional.softmax(outputs.logits, dim=-1)
confidences, predictions = torch.max(probs, dim=1)
result = {"confidence": confidences.item(),
"prediction": predictions.item()}
logger.debug(f"Inference result: {result}")
return result
except Exception as e:
logger.error(f"Error during inference: {e}")
raise e
def postprocess(self, inference_output):
logger.info("Postprocessing inference output.")
logger.debug(f"Postprocessing result: {inference_output}")
return [inference_output]torchserve==0.6.0
torch-model-archiver==0.6.0
transformers==4.47.1
torch==2.4.0+cu121# Stage 0: Fetch Model Files
FROM alpine/git AS fetcher
RUN apk add --no-cache git
RUN git clone https://huggingface.co/bert-base-uncased /model
# Stage 1: Build Stage
FROM pytorch/torchserve:latest AS build
RUN pip install transformers
RUN mkdir -p /home/model-server/model-store /home/model-server/code
COPY requirements.txt /home/model-server/
RUN pip install -r /home/model-server/requirements.txt
COPY --from=fetcher /model /home/model-server/model-store/bert
COPY handler.py /home/model-server/code/handler.py
# Archive the model
RUN torch-model-archiver \
--model-name bert_seq_class \
--version 1.0 \
--serialized-file /home/model-server/model-store/bert/pytorch_model.bin \
--handler /home/model-server/code/handler.py \
--extra-files "/home/model-server/model-store/bert/config.json,/home/model-server/model-store/bert/tokenizer.json,/home/model-server/model-store/bert/tokenizer_config.json,/home/model-server/model-store/bert/vocab.txt" \
--export-path /home/model-server/model-store
# Stage 2: Runtime Stage
FROM pytorch/torchserve:latest-gpu
COPY requirements.txt /home/model-server/
RUN pip install -r /home/model-server/requirements.txt
# Copy model archive and configuration from the build stage
COPY --from=build /home/model-server/model-store /home/model-server/model-store
EXPOSE 8080
EXPOSE 8081
# Start TorchServe
CMD ["torchserve", "--start", "--model-store", "/home/model-server/model-store", "--models", "bert_seq_class=bert_seq_class.mar"]docker build -t torchserve-bert-model .
docker run -p 8080:8080 -p 8081:8081 --name torchserve-bert-model torchserve-bert-modeldocker exec -it torchserve-bert-model bash%%bash
curl -X POST http://localhost:8080/predictions/bert_seq_class -H "Content-Type: application/json" -d '{"text": "I love using TorchServe with Hugging Face models!"}'
{
"confidence": 0.5290595293045044,
"prediction": 1class Hook():
def __init__(self, m):
self.hook = m.register_forward_hook(self.hook_func)
def hook_func(self, m, i, o): self.stored = o.detach().clone()
def __enter__(self, *args): return self # 'just give me the hook'
def __exit__(self, *args): self.hook.remove() # remove the hook to avoid memory leak
# use as follows
with Hook(learn.model[0]) as hook: # will register forward hook on learn.model[0]
with torch.no_grad(): output = learn.model.eval()(x.cuda())
act = hook.stored
# This will allow you to get dot product of weight matrix with the activations (2,k activations) @ (k activations, rows, cols)
# Can then look which pixels contributed to model's prediction by plotting this map
cam_map = torch.einsum('ck,kij->cij',learn.model[1][-1].weight,act)class HookBwd():
def __init__(self, m):
self.hook = m.register_backward_hook(self.hook_func)
def hook_func(self, m, gi, go):
"""Will access gradients of the input gi and output go of the m module"""
self.stored = go[0].detach().clone
def __enter__(self, *args): return self
def __exit__(self, *args): self.hook.remove()cls = 1
with HookBwd(learn.model[0]) as hookg:
with Hook(learn.model[0]) as hook:
output = learn.model.eval()(x.cuda())
act = hook.stored
output[0,cls].backward()
grad = hookg.stored
# can then get product of gradients and activations
w = grad[0].mean(dim=[1,2], keepdim=True)
cam_map = (w * act[0]).sum(0)from transformers import Trainer, BertForSequenceClassification, BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
class Hook():
def __init__(self, m, print_every=100):
self.hook = m.register_forward_hook(self.hook_func)
self.counter = 0
self.print_every = print_every
def hook_func(self,m,i,o):
if self.counter % self.print_every == 0:
input_shape = [tensor.shape for tensor in i]
output_shape = o.shape if isinstance(o, torch.Tensor) else [tensor.shape for tensor in o]
print(f"Layer: {m}, Input shape: {input_shape}, Output shape: {output_shape}")
self.counter += 1
def __enter__(self, *args): return self
def __exit__(self, *args): self.hook.remove()
text = "..."
inputs = tokenizer(text, return_tensors='pt')
with Hook(model.bert.encoder.layer[0].attention) as hookf:
outputs = model(**inputs)
# Then use Trainer or SFTTrainer as always ...
trainer = Trainer(...)
trainer.train()
# Will print input/output shapes every print_every iterations. Can log these, of course.import torch
class AdamOptimizer:
def __init__(self, params, lr=1e-3, beta1=0.9, beta2=0.999, epsilon=1e-8, weight_decay=0):
"""
Adam optimizer from scratch for PyTorch.
Args:
params (iterable): The parameters to optimize (typically model.parameters()).
lr (float): Learning rate (default 1e-3).
beta1 (float): Exponential decay rate for first moment estimate (default 0.9).
beta2 (float): Exponential decay rate for second moment estimate (default 0.999).
epsilon (float): Term added to the denominator to avoid division by zero (default 1e-8).
weight_decay (float): Weight decay (L2 penalty) (default 0).
"""
self.params = list(params)
self.lr = lr
self.beta1 = beta1 # weight on past param mean
self.beta2 = beta2 # weight on past param var
self.epsilon = epsilon
self.weight_decay = weight_decay # how much of param to include in the grad
# Initialize moment estimates
self.m = [torch.zeros_like(param) for param in self.params] # First moment (m)
self.v = [torch.zeros_like(param) for param in self.params] # Second moment (v)
# Time step counter
self.t = 0
def step(self):
"""
Perform a single optimization step.
"""
self.t += 1 # important for bias correction below
with torch.no_grad():
for i, param in enumerate(self.params):
if param.grad is None: continue
# Get the gradients for the current parameter
grad = param.grad
# Apply weight decay (L2 penalty): weighting grad linearly ~ weighting weight quadratically w/ L2
if self.weight_decay != 0: grad = grad + self.weight_decay * param
# Update biased first and second moment estimates
self.m[i] = self.beta1 * self.m[i] + (1 - self.beta1) * grad
self.v[i] = self.beta2 * self.v[i] + (1 - self.beta2) * grad**2
# Bias correction
m_hat = self.m[i] / (1 - self.beta1**self.t)
v_hat = self.v[i] / (1 - self.beta2**self.t)
# Update parameters
param -= self.lr * m_hat / (torch.sqrt(v_hat) + self.epsilon)
def zero_grad(self):
"""
Reset gradients of all parameters.
"""
for param in self.params:
if param.grad is not None:
param.grad.zero_()
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets, transforms
# Define a simple neural network
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(28 * 28, 256)
self.fc2 = nn.Linear(256, 10)
def forward(self, x):
x = x.view(-1, 28 * 28) # Flatten the input
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
# Set up data loaders for MNIST
transform = transforms.Compose([transforms.ToTensor()])
train_dataset = datasets.MNIST(root='data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
test_dataset = datasets.MNIST(root='data', train=False, download=True, transform=transform)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=1000, shuffle=False)
# Initialize the network and optimizer
model = SimpleNet()
optimizer = AdamOptimizer(model.parameters(), lr=1e-3)
# Define loss function
criterion = nn.CrossEntropyLoss()
# Training loop
for epoch in range(1, 6): # Run for 5 epochs
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
# Zero gradients
optimizer.zero_grad()
# Forward pass
output = model(data)
loss = criterion(output, target)
# Backward pass
loss.backward()
# Optimization step
optimizer.step()
# Print progress occasionally
if batch_idx % 200 == 0:
print(f'Epoch {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)}] Loss: {loss.item():.6f}')
# Evaluation on test data
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
output = model(data)
test_loss += criterion(output, target).item() # Sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # Get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader)
accuracy = correct / len(test_loader.dataset)
print(f'\nTest set: Average loss: {test_loss:.4f}, Accuracy: {correct}/{len(test_loader.dataset)} ({accuracy * 100:.2f}%)\n')Epoch 1 [0/60000] Loss: 2.307041
Epoch 1 [12800/60000] Loss: 0.193796
Epoch 1 [25600/60000] Loss: 0.254285
Epoch 1 [38400/60000] Loss: 0.195109
Epoch 1 [51200/60000] Loss: 0.142228
Test set: Average loss: 0.1497, Accuracy: 9551/10000 (95.51%)
Epoch 2 [0/60000] Loss: 0.056716
Epoch 2 [12800/60000] Loss: 0.116285
Epoch 2 [25600/60000] Loss: 0.286116
Epoch 2 [38400/60000] Loss: 0.097069
Epoch 2 [51200/60000] Loss: 0.040939
Test set: Average loss: 0.1021, Accuracy: 9698/10000 (96.98%)
Epoch 3 [0/60000] Loss: 0.152332
Epoch 3 [12800/60000] Loss: 0.059672
Epoch 3 [25600/60000] Loss: 0.074841
Epoch 3 [38400/60000] Loss: 0.116336
Epoch 3 [51200/60000] Loss: 0.092772
Test set: Average loss: 0.0838, Accuracy: 9746/10000 (97.46%)
Epoch 4 [0/60000] Loss: 0.078431
Epoch 4 [12800/60000] Loss: 0.036434
Epoch 4 [25600/60000] Loss: 0.119966
Epoch 4 [38400/60000] Loss: 0.120010
Epoch 4 [51200/60000] Loss: 0.054376
Test set: Average loss: 0.0735, Accuracy: 9771/10000 (97.71%)
Epoch 5 [0/60000] Loss: 0.042105
Epoch 5 [12800/60000] Loss: 0.036648
Epoch 5 [25600/60000] Loss: 0.033848
Epoch 5 [38400/60000] Loss: 0.043520
Epoch 5 [51200/60000] Loss: 0.071161
Test set: Average loss: 0.0677, Accuracy: 9792/10000 (97.92%)
import torch
class AdamOptimizer:
def init(self, params, lr=1e-3, beta1=0.9, beta2=0.999, epsilon=1e-8, weight_decay=0):
""" Adam optimizer from scratch for PyTorch, now supporting parameter groups.
Args:
params (iterable or list of dict):
If iterable of torch.Tensor, use single hyperparameters (lr, weight_decay, etc.)
If list of dict, each dict defines a parameter group, e.g.:
{
'params': [list_of_parameters],
'lr': ...,
'beta1': ...,
'beta2': ...,
'epsilon': ...,
'weight_decay': ...
}
lr (float): Default learning rate (used if lr not specified in a param group).
beta1 (float): Exponential decay rate for first moment estimate (default 0.9).
beta2 (float): Exponential decay rate for second moment estimate (default 0.999).
epsilon (float): Term added to the denominator to avoid division by zero (default 1e-8).
weight_decay (float): Weight decay (L2 penalty) (default 0).
"""
# Prepare list of param groups
# If 'params' is just an iterable of Tensors, make a single group
if isinstance(params, (list, tuple)) and len(params) > 0 and isinstance(params[0], dict):
# Already a list of parameter groups
self.param_groups = params
else:
# Single parameter group dictionary
self.param_groups = [{
'params': params,
'lr': lr,
'beta1': beta1,
'beta2': beta2,
'epsilon': epsilon,
'weight_decay': weight_decay
}]
# Convert each 'params' field to a list, and build storage for m, v
for group in self.param_groups:
group.setdefault('lr', lr)
group.setdefault('beta1', beta1)
group.setdefault('beta2', beta2)
group.setdefault('epsilon', epsilon)
group.setdefault('weight_decay', weight_decay)
# Make sure 'params' is a list of actual tensors
group['params'] = list(group['params'])
# Initialize first and second moment for all params in this group
group['m'] = [torch.zeros_like(p) for p in group['params']]
group['v'] = [torch.zeros_like(p) for p in group['params']]
# Global time step (can be tracked per group if desired)
self.t = 0
def step(self):
"""
Perform a single optimization step for all parameter groups.
"""
self.t += 1 # increment global time step
with torch.no_grad():
for group in self.param_groups:
lr = group['lr']
beta1 = group['beta1']
beta2 = group['beta2']
epsilon = group['epsilon']
weight_decay = group['weight_decay']
# Update parameters in this group
for i, param in enumerate(group['params']):
if param.grad is None:
continue
grad = param.grad
# Weight decay
if weight_decay != 0:
grad = grad + weight_decay * param
# Update biased first and second moment estimates
group['m'][i] = beta1 * group['m'][i] + (1 - beta1) * grad
group['v'][i] = beta2 * group['v'][i] + (1 - beta2) * (grad ** 2)
# Bias corrections
m_hat = group['m'][i] / (1 - beta1 ** self.t)
v_hat = group['v'][i] / (1 - beta2 ** self.t)
# Update parameter
param -= lr * m_hat / (torch.sqrt(v_hat) + epsilon)
def zero_grad(self):
"""
Reset gradients of all parameters in all parameter groups.
"""
for group in self.param_groups:
for param in group['params']:
if param.grad is not None:
param.grad.zero_()nn.init.kaiming_uniform_.
model.apply.import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# Define a custom CNN
class CustomCNN(nn.Module):
def __init__(self, num_classes=10):
super(CustomCNN, self).__init__()
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(16)
self.conv2 = nn.Conv2d(16, 32, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(32)
self.fc1 = nn.Linear(32 * 8 * 8, 128)
self.fc2 = nn.Linear(128, num_classes)
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x))) # Conv1 -> BN -> ReLU
x = F.max_pool2d(x, 2) # 32x32 -> 16x16
x = F.relu(self.bn2(self.conv2(x))) # Conv2 -> BN -> ReLU
x = F.max_pool2d(x, 2) # 16x16 -> 8x8
x = x.view(x.size(0), -1) # Flatten
x = F.relu(self.fc1(x)) # FC1 -> ReLU
x = self.fc2(x) # FC2
return x
# Initialize the model
model = CustomCNN(num_classes=10)
# Define initialization function
def initialize_weights(m):
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
if m.bias is not None:
nn.init.zeros_(m.bias)
# Apply initialization
model.apply(initialize_weights)
# Print initialized weights for verification
print("Conv1 weights:", model.conv1.weight)
print("BatchNorm1 weights:", model.bn1.weight)
print("FC1 weights:", model.fc1.weight)unbiased=False. This is because the biased estimator (dividing by N instead of N-1 in the variance formula) is MLE estimator of variance under iid and normally distributed assumptions. Also, the data will be normalized consistently even if batch size is 1.
import torch
import torch.nn as nn
class BatchNorm2d(nn.Module):
def __init__(self, num_features, eps=1e-5, momentum=0.1, affine=True):
super(BatchNorm2d, self).__init__()
self.num_features = num_features
self.eps = eps
self.momentum = momentum
# Learnable affine parameters: gamma (scale) and beta (shift)
self.gamma, self.beta = None, None
if affine:
self.gamma = nn.Parameter(torch.ones(num_features)) # scale parameter
self.beta = nn.Parameter(torch.zeros(num_features)) # shift parameter
# Running statistics for mean and variance
self.running_mean = torch.zeros(num_features) # mean 0
self.running_var = torch.ones(num_features) # var 1
def forward(self, x):
# Calculate mean and variance across the batch and spatial dimensions (H, W)
batch_mean = x.mean(dim=(0, 2, 3), keepdim=True) # mean across N, H, W for each channel
batch_var = x.var(dim=(0, 2, 3), unbiased=False, keepdim=True) # variance across N, H, W for each channel
# Update running statistics (mean and variance): See batch_mean dimension note below
with torch.no_grad(): # running mean/var are updated via moving avg approach, not SGD
self.running_mean = (1 - self.momentum) * self.running_mean + self.momentum * batch_mean.squeeze()
self.running_var = (1 - self.momentum) * self.running_var + self.momentum * batch_var.squeeze()
# During training, we use the batch statistics
if self.training:
mean = batch_mean
var = batch_var
else:
# During inference, we use the running statistics
mean = self.running_mean.view(1, self.num_features, 1, 1)
var = self.running_var.view(1, self.num_features, 1, 1)
# mean = self.running_mean[None, :, None, None] # Alternatively...
# var = self.running_var[None, :, None, None]
# Normalize the input
x_normalized = (x - mean) / torch.sqrt(var + self.eps)
# Apply the affine transformation (scaling and shifting)
if self.gamma is not None and self.beta is not None:
x_normalized = self.gamma.view(1, self.num_features, 1, 1) * x_normalized + self.beta.view(1, self.num_features, 1, 1)
#x_normalized = self.gamma[None, :, None, None] * x_normalized + self.beta[None,:, None, None] # Alternatively
return x_normalized
# Example usage
if __name__ == "__main__":
# Create random input with shape (batch_size, num_features, height, width)
x = torch.randn(32, 64, 28, 28) # batch_size=32, num_features=64 (channels), height=28, width=28
# Instantiate the BatchNorm2d layer
batch_norm = BatchNorm2d(num_features=64)
# Forward pass through the batch norm layer
output = batch_norm(x)
print(f"Input shape: {x.shape}")
print(f"Output shape: {output.shape}")model.train() and model.eval() as in# Training phase
model.train()
for data, target in train_loader:
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
# Evaluation phase
model.eval()
with torch.no_grad():
for data, target in test_loader:
output = model(data)
# Compute metrics
# Or after loading a model:
torch.save(model.state_dict(), 'model.pth')
model.load_state_dict(torch.load('model.pth'))
model.eval() # Set to evaluation mode after loadingclass CNNNet(nn.Module):
def __init__(self):
super(CNNNet, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3)
self.dropout = nn.Dropout2d(p=0.25)
self.fc1 = nn.Linear(32 * 26 * 26, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.dropout(x)
x = x.view(x.size(0), -1)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return xThe major architectural improvement used in transformers according to Andrej.
Instead adding a vector to the token embeddings vector, apply a rotation. Take the token embedding and rotate it by position*theta (ex, 4xtheta if there are 4 tokens appearing before the token in question).

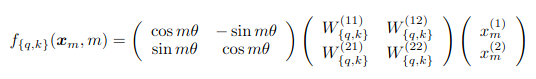
Apply the linear transformations to get the query and key vectors before applying the rotation matrix: want embeddings for relative positions between tokens.
In terms of notation, note that frequencies are represented as:
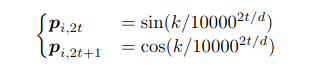
Range of Frequencies: By using a range of frequencies, the model can capture positional information at different scales. Lower frequencies capture long-range dependencies, while higher frequencies capture short-range dependencies.
An inefficient implementation would rely on applying matrix multiplication to each pair of coordinates as below:
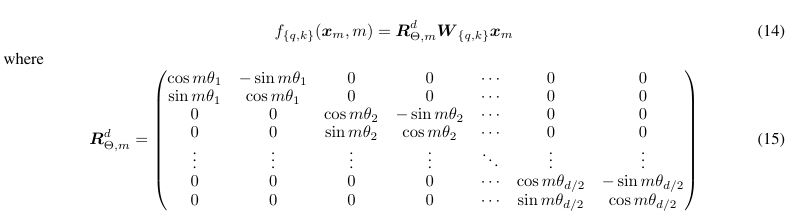
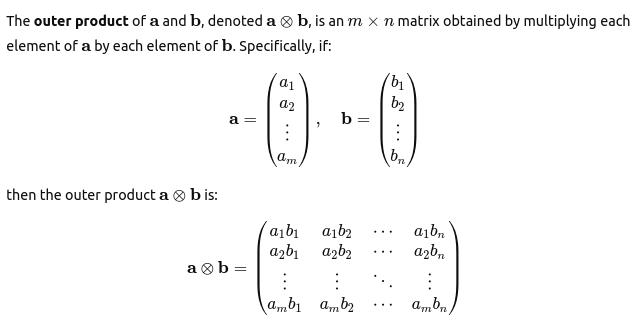

import torch
import torch.nn as nn
class RotaryPositionalEmbedding(nn.Module):
def __init__(self, dim, base=10000):
super().__init__()
self.dim, self.base = dim, base
# precompute the sinusoidal embeddings: needed for eq. 4 in paper,
# position for denominator derived in forward once know seq_len
inv_freq = 1.0/(self.base**(torch.arange(0,dim,2).float()/dim))
self.register_buffer('inv_freq',inv_freq)
def forward(self, x):
# Compute positional embeddings
seq_len = x.size(1)
pos = torch.arange(seq_len, device=x.device, dtype=self.inv_freq.dtype)
sinusoid_inp = torch.outer(pos, self.inv_freq) # see equation (34) above; [seq_len, dim // 2]
sin_emb = sinusoid_inp.sin()[None, :, :] # Shape: [1, seq_len, dim // 2]
cos_emb = sinusoid_inp.cos()[None, :, :] # Shape: [1, seq_len, dim // 2]
# Split the input tensor into even and odd parts
x_even = x[:, :, ::2] # Even indices
x_odd = x[:, :, 1::2] # Odd indices
# Apply rotary embeddings: best to follow simple 2D setup for intuition
x_rotated = torch.zeros_like(x)
x_rotated[:, :, ::2] = x_even * cos_emb - x_odd * sin_emb
x_rotated[:, :, 1::2] = x_even * sin_emb + x_odd * cos_emb
return x_rotated
batch_size, seq_len, dim = 2, 10, 64
x = torch.randn(batch_size, seq_len, dim)
rotary_pos_emb = RotaryPositionalEmbedding(dim)
x_rotary = rotary_pos_emb(x)
print("Input shape:", x.shape)
print("Output shape:", x_rotary.shape)Input shape: torch.Size([2, 10, 64])
Output shape: torch.Size([2, 10, 64])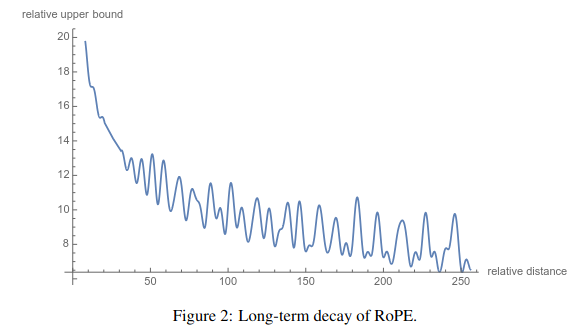
attn_scores = torch.matmul(q, k.transpose(-2, -1)) * self.head_dim ** -0.5 looks the same as always BUT AGAIN, q’s seq_len==1 in [batch_size, num_heads, seq_len, seq_len_total], and matmul occurs with full k constructed using the cache: there’s no need to recompute full k @ v, just get the next token since the previous computations are cached.attn_output = torch.matmul(attn_probs, v).forward would only have access to the current token’s keys and values. This would mean the model couldn’t attend to previous tokens, leading to incorrect outputs.import torch
import torch.nn as nn
class KVCache:
def __init__(self):
self.k = None # [batch_size, num_heads, seq_len_cache, head_dim]
self.v = None
def update(self, k_new, v_new):
# Append new keys and values to cache
if self.k is None:
self.k = k_new
self.v = v_new
else:
self.k = torch.cat([self.k, k_new], dim=2)
self.v = torch.cat([self.v, v_new], dim=2)
def get(self):
return self.k, self.v
class MultiheadSelfAttention(nn.Module):
def __init__(self, embed_dim, num_heads):
super().__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
self.qkv_proj = nn.Linear(embed_dim, 3 * embed_dim)
self.out_proj = nn.Linear(embed_dim, embed_dim)
def forward(self, x, kv_cache=None):
batch_size, seq_len, embed_dim = x.size()
# Project input to Q, K, V
# IMPORTANT: note seq_len == 1, see generation loop below, the main point of the cache
qkv = self.qkv_proj(x) # [batch_size, seq_len, 3 * embed_dim]
q, k_new, v_new = qkv.chunk(3, dim=-1)
# Reshape and transpose for multi-head attention
q = q.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2) # [batch_size, num_heads, 1, head_dim]
k_new = k_new.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
v_new = v_new.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
### --- Start: KV Cache code modifications --- ###
if kv_cache is not None:
cached_k, cached_v = kv_cache.get()
if cached_k is not None: # 1/2 update for the computations
k = torch.cat([cached_k, k_new], dim=2)
v = torch.cat([cached_v, v_new], dim=2)
else:
k = k_new
v = v_new
kv_cache.update(k_new,v_new) # 2/2 update for the cache
else:
k = k_new
v = v_new
# Compute attention scores: same as always BUT AGAIN, q's seq_len==1 in [batch_size, num_heads, seq_len, seq_len_total]
attn_scores = torch.matmul(q, k.transpose(-2, -1)) * self.head_dim ** -0.5
# Create causal mask: note that unlike in a vanilla transformer with a registered buffer of size seq_len by seq_len, it's seq_len by seq_len_total
seq_len_total = k.size(2)
causal_mask = torch.tril(torch.ones(seq_len, seq_len_total, device=x.device)).bool() # [seq_len, seq_len_total]
attn_scores = attn_scores.masked_fill(~causal_mask.unsqueeze(0).unsqueeze(0), float('-inf'))
### --- End: KV Cache code modifications --- ###
# Compute attention probabilities
attn_probs = torch.softmax(attn_scores, dim=-1)
# Compute attention output
attn_output = torch.matmul(attn_probs, v) # [batch_size, num_heads, seq_len, head_dim]
# Reshape and project output
attn_output = attn_output.transpose(1, 2).contiguous().view(batch_size, seq_len, self.embed_dim)
output = self.out_proj(attn_output)
return output
class TransformerDecoderLayer(nn.Module):
def __init__(self, embed_dim, num_heads):
super().__init__()
self.self_attn = MultiheadSelfAttention(embed_dim, num_heads)
self.norm1 = nn.LayerNorm(embed_dim)
self.ffn = nn.Sequential(
nn.Linear(embed_dim, 4 * embed_dim),
nn.GELU(),
nn.Linear(4 * embed_dim, embed_dim),
)
self.norm2 = nn.LayerNorm(embed_dim)
def forward(self, x, kv_cache=None):
# Self-attention with KV cache
attn_output = self.self_attn(x, kv_cache=kv_cache)
x = x + attn_output
x = self.norm1(x)
# Feed-forward network
ffn_output = self.ffn(x)
x = x + ffn_output
x = self.norm2(x)
return x
# Example usage
embed_dim = 512
num_heads = 8
decoder_layer = TransformerDecoderLayer(embed_dim, num_heads)
kv_cache = KVCache()
# Initial input token
input_token = torch.randn(1, 1, embed_dim) # [batch_size, seq_len=1, embed_dim]
# Autoregressive generation loop
output_tokens = []
for _ in range(10):
output = decoder_layer(input_token, kv_cache=kv_cache)
output_tokens.append(output)
input_token = output[:, -1:, :] # Use the last token as the next input; MUST provide kv_cache above for this to work
output_sequence = torch.cat(output_tokens, dim=1)
print("Generated sequence shape:", output_sequence.shape)import torch
import torch.nn as nn
class LoRALinear(nn.Module):
"""
A LoRA (Low-Rank Adaptation) layer that wraps an existing nn.Linear layer.
It adds a low-rank update to the output of the original linear layer.
"""
def __init__(self, original_linear, r=4, alpha = 1.0):
super().__init__()
self.linear = original_linear
self.r = r
self.alpha = alpha
# Key step 1/4: Initialize LoRA parameters
if r > 0:
in_features = original_linear.in_features
out_features = original_linear.out_features
# initialize A and B low-rank matrices
self.lora_A = nn.Parameter(torch.zeros(in_features,r))
self.lora_B = nn.Parameter(torch.zeros(r,out_features))
# Use normal init (mean 0, std 0.02)
nn.init.normal_(self.lora_A, std=0.02)
nn.init.normal_(self.lora_B, std=0.02)
# Scaling factor for LoRA update
self.scaling = self.alpha/self.r
else:
self.lora_A = None
self.lora_B = None
self.scaling = 1.0
def forward(self, x):
result = self.linear(x)
# Key step 2/4: Use LoRA parameters in matmuls
if self.r > 0:
# ((bs,in_features) @ (in_features,r)) @ (r,out_features) -> (bs, out_features)
lora_update = (x @ self.lora_A) @ self.lora_B
lora_update *= self.scaling
result += lora_update
return result
# Key step 3/4: Replace nn.Linear layers with nn.LoRALinear layers
def replace_linear_with_lora(model, r=4, alpha=1.0):
"""
Recursively replace nn.Linear layers with LoRALinear layers in the model.
"""
for name, module in model.named_children():
if isinstance(module,nn.Linear):
setattr(model,name,LoRALinear(module,r,alpha))
else: # recursively apply to child modules
replace_linear_with_lora(module, r, alpha)
return model
def get_lora_params(model):
"""
Retrieve all LoRA parameters from the model.
"""
lora_parameters = []
for module in model.modules():
if isinstance(module, LoRALinear):
lora_parameters.extend([module.lora_A, module.lora_B])
return lora_parameters
# Example Usage
class SimpleModel(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(SimpleModel, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
out = self.relu(self.fc1(x))
out = self.fc2(out)
return out
model = SimpleModel(input_dim=128, hidden_dim=64, output_dim=10)
model = replace_linear_with_lora(model, r=4, alpha=1.0)
# Key step 4/4: Only do backprop on the LoRA parameters
lora_parameters = get_lora_params(model)
optimizer = torch.optim.Adam(lora_parameters, lr=1e-3)
# Training loop followsimport torch
import torch.nn as nn
class QLoRALinear(nn.Module):
"""
A QLoRA (Quantized Low-Rank Adaptation) layer that wraps an existing quantized nn.Linear layer.
It adds a low-rank update to the output of the original quantized linear layer.
"""
def __init__(self, original_linear, r=4, alpha=1.0):
super().__init__()
# Quantize the original linear layer's weights to 4-bit
...
self.linear.weight.data = self.quantize_weights(self.linear.weight.data)
self.linear.bias = original_linear.bias # Bias remains in full precision
...
if r > 0:
...
else:
...
def quantize_weights(self, weight, num_bits=4):
"""
Quantizes the weights to the specified number of bits.
"""
qmin = 0
qmax = 2**num_bits - 1
min_val, max_val = weight.min(),weight.max()
scale = (max_val-min_val)/(qmax-qmin)
zero_point = qmin - min_val/scale
q_weight = torch.clamp((weight/scale + zero_point).round(),qmin,qmax)
#q_weight = (q_weight - zero_point) * scale
return q_weight
def forward(self, x):
...
def replace_linear_with_qlora(model, r=4, alpha=1.0):
"""Swap LoRALinear with QLoRALinear"""
def get_qlora_params(model):
"""Swap LoRALinear with QLoRALinear"""
# Example Usage
class SimpleModel(nn.Module):
"""Same"""
model = SimpleModel(input_dim=128, hidden_dim=64, output_dim=10)
model = replace_linear_with_qlora(model, r=4, alpha=1.0)
# Only do backprop on the QLoRA parameters
qlora_parameters = get_qlora_params(model)
optimizer = torch.optim.Adam(qlora_parameters, lr=1e-3)
# Training loop follows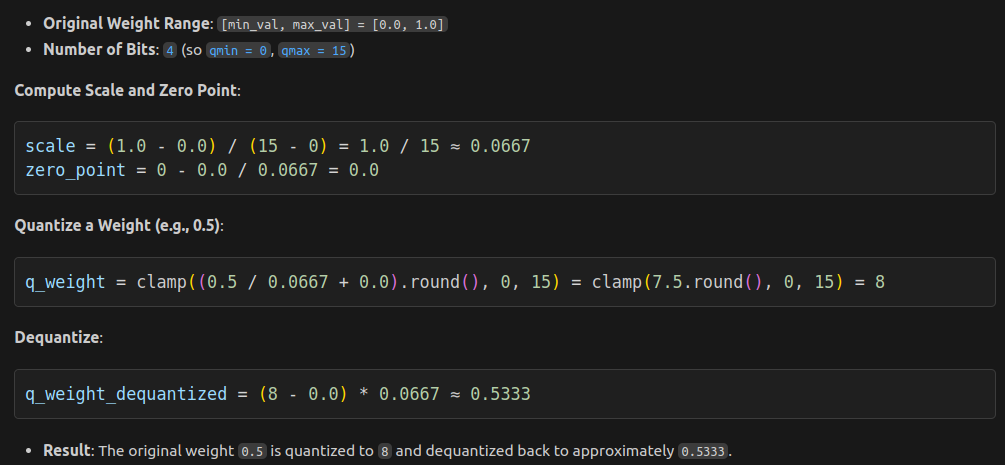
import torch
import torch.nn as nn
import bitsandbytes as bnb
class QLoRALinear(nn.Module):
"""
A QLoRA (Quantized Low-Rank Adaptation) layer that wraps an existing nn.Linear layer.
It quantizes the original linear layer and adds a low-rank update.
"""
def __init__(self, original_linear, r=4, alpha=1.0, num_bits=4):
super().__init__()
self.r = r
self.alpha = alpha
if num_bits == 8:
self.linear = bnb.nn.Linear8bitLt(
original_linear.in_features,
original_linear.out_features,
bias=original_linear.bias is not None,
has_fp16_weights=False,
threshold=6.0
)
elif num_bits == 4:
self.linear = bnb.nn.Linear4bit(
original_linear.in_features,
original_linear.out_features,
bias = original_linear.bias is not None,
compute_dtype=torch.float16
)
else:
raise ValueError(f"Unsupported num_bits: {num_bits}. Supported values are 4 and 8.")
self.linear.weight.data = original_linear.weight.data.clone()
if original_linear.bias is not None:
self.linear.bias.data = original_linear.bias.data.clone()
if r > 0: ... else:...
# Freeze the quantized weights
for param in self.linear.parameters():
param.requires_grad = False
# Quantize the original linear layer
self.linear = quantization.QuantWrapper(original_linear)
# Dynamic quantization quantizes weights ahead of time and quantizes activations on-the-fly during forward pass
self.linear.qconfig = quantization.default_dynamic_qconfig
quantization.prepare(self.linear, inplace=True) # collect stats needed for quantization
quantization.convert(self.linear, inplace=True) # replace original operations with quantized counterparts
# Load a pre-trained tokenizer
import warnings
warnings.filterwarnings("ignore", category=FutureWarning, module="huggingface_hub")
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')# Tokenizing text
text = "Hello, how are you?"
encoded_input = tokenizer(text, padding=True, truncation=True, return_tensors='pt')
print(encoded_input){'input_ids': tensor([[ 101, 7592, 1010, 2129, 2024, 2017, 1029, 102]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1]])}# Handling batch inputs
texts = ["Hello, how are you?", "I am fine, thank you!"]
encoded_inputs = tokenizer(texts, padding=True, truncation=True, return_tensors='pt')
print(encoded_inputs){'input_ids': tensor([[ 101, 7592, 1010, 2129, 2024, 2017, 1029, 102, 0],
[ 101, 1045, 2572, 2986, 1010, 4067, 2017, 999, 102]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1]])}# Decoding tokens back to text
decoded_text = tokenizer.decode(encoded_input['input_ids'][0])
print(decoded_text)[CLS] hello, how are you? [SEP]# Adding new tokens:
new_tokens = ['newtoken1', 'newtoken2']
tokenizer.add_tokens(new_tokens)
model.resize_token_embeddings(len(tokenizer))from transformers import AutoTokenizer
#tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
tokenizer = AutoTokenizer.from_pretrained("HuggingFaceH4/zephyr-7b-beta")
chat = [
{"role": "user", "content": "Hello, how are you?"},
{"role": "assistant", "content": "I'm doing great. How can I help you today?"},
{"role": "user", "content": "I'd like to show off how chat templating works!"},
]
tokenizer.apply_chat_template(chat, tokenize=False)"<|user|>\nHello, how are you?</s>\n<|assistant|>\nI'm doing great. How can I help you today?</s>\n<|user|>\nI'd like to show off how chat templating works!</s>\n"messages = [
{"role": "user", "content": "Hi there!"},
{"role": "assistant", "content": "Nice to meet you!"},
{"role": "user", "content": "Can I ask a question?"}
]
tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=False)
'<|user|>\nHi there!</s>\n<|assistant|>\nNice to meet you!</s>\n<|user|>\nCan I ask a question?</s>\n'tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)'<|user|>\nHi there!</s>\n<|assistant|>\nNice to meet you!</s>\n<|user|>\nCan I ask a question?</s>\n<|assistant|>\n'# ---Step 0: Prepare the data by finding the prompt and formatting a column ('text' for
# regular SFT, 'messages' for instruction ft, etc), shuffling and splitting it ---
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
from peft import LoraConfig, prepare_model_for_kbit_training, get_peft_config,get_peft_model
model_name = HF_MODEL_ID
# ---Step 1: Initialize BitsAndBytesConfig and feed it to the model upon load---
bnb_config = BitsAndBytesConfig( #Q in QLoRA
load_in_4bit=True, # Use 4-bit precision model loading
bnb_4bit_quant_type="nf4", # Quantization type
bnb_4bit_compute_dtype="float16", # Compute dtype
bnb_4bit_use_double_quant=True, # Apply nested quantization
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
# Leave this out for regular SFT
quantization_config=bnb_config,
)
model.config.use_cache = False
model.config.pretraining_tp = 1
# ---Step 2: Load the tokenizer---
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
tokenizer.pad_token = "<PAD>"
tokenizer.padding_side = "left"
# ---Step 3: Initialize LoraConfig and i.) peft.prepare_model_for_kbit_training and ii.) peft.get_peft_model---
peft_config = LoraConfig(
lora_alpha=32,
lora_dropout=0.1,
r=128,
bias="none",
task_type="CAUSAL_LM",
target_modules= # Layers to target
["k_proj", "gate_proj", "v_proj", "up_proj", "q_proj", "o_proj", "down_proj"]
)
model = prepare_model_for_kbit_training(model)
model = get_peft_model(model, peft_config)
# ---Step 4: Define TrainingArguments, set up SFTTrainer, trainer.train()---
from transformers import DataCollatorForLanguageModeling
training_arguments = TrainingArguments(
output_dir=output_dir,
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
optim="paged_adamw_32bit",
learning_rate=2e-4,
lr_scheduler_type="cosine",
num_train_epochs = 10.0,
logging_steps=10,
fp16=True,
gradient_checkpointing=True
)
trainer = SFTTrainer(
model=model,
train_dataset=dataset['train'],
eval_dataset=dataset['valid'],
data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False),
# peft_config=peft_config,
dataset_text_field="text",
max_seq_length=256,
tokenizer=tokenizer,
args=training_arguments,
packing=True,
)
trainer.train()
# NOTE: SFTTrainer will automatically send logs to wandb set up via
# import wandb; wandb.login(); %env WANDB_PROJECT=sql-fine-tuning
# ---Step 5: Save QLoRA weights and merge---
trainer.model.save_pretrained(output_dir)
from peft import AutoPeftModelForCausalLM
model = AutoPeftModelForCausalLM.from_pretrained(output_dir, device_map="auto", torch_dtype=torch.bfloat16)
model = model.merge_and_unload()
output_merged_dir = os.path.join(output_dir, "final_merged_checkpoint")
model.save_pretrained(output_merged_dir, safe_serialization=True)
# NOTE: In the future, can load this final merged model without knowing the QLoRA configurations
# ---Step x: Can use the merged model to make predictions as follows---
from transformers import pipeline
# Use our predefined prompt template
prompt = """<|user|>
Tell me something about Large Language Models.</s>
<|assistant|>
"""
# Run our instruction-tuned model
pipe = pipeline(task="text-generation", model=merged_model, tokenizer=tokenizer)
print(pipe(prompt)[0]["generated_text"])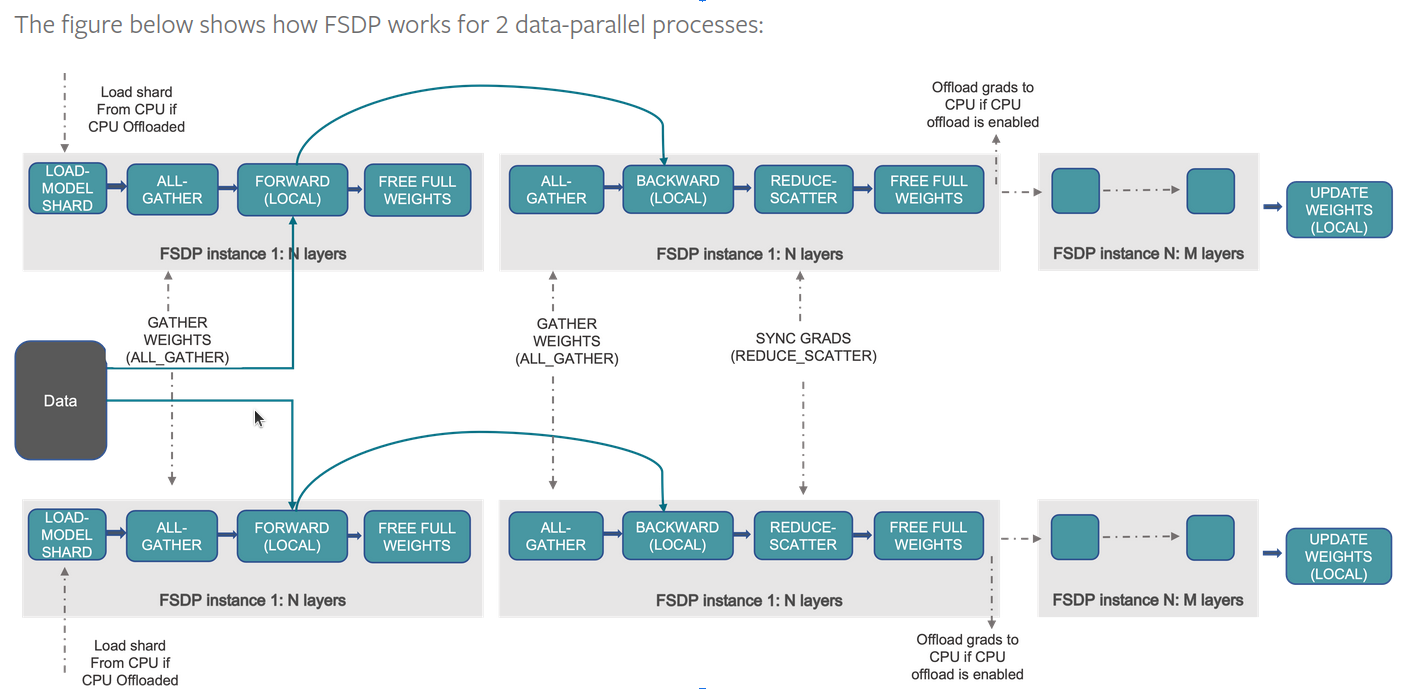
sharding_strategy
offload_params
fsdp_offload_params allows gradients and model parameters to be offloaded into RAM. Can train much bigger model, but can be very slow.See https://huggingface.co/docs/accelerate/en/usage_guides/explore for script and config pairings for various settings.
Main commands in the CLI interface
accelerate config: configure the environmentaccelerate estimate-memory: estimate vRAM requirementsaccelerate launch: launch the scriptMain basic script modifications
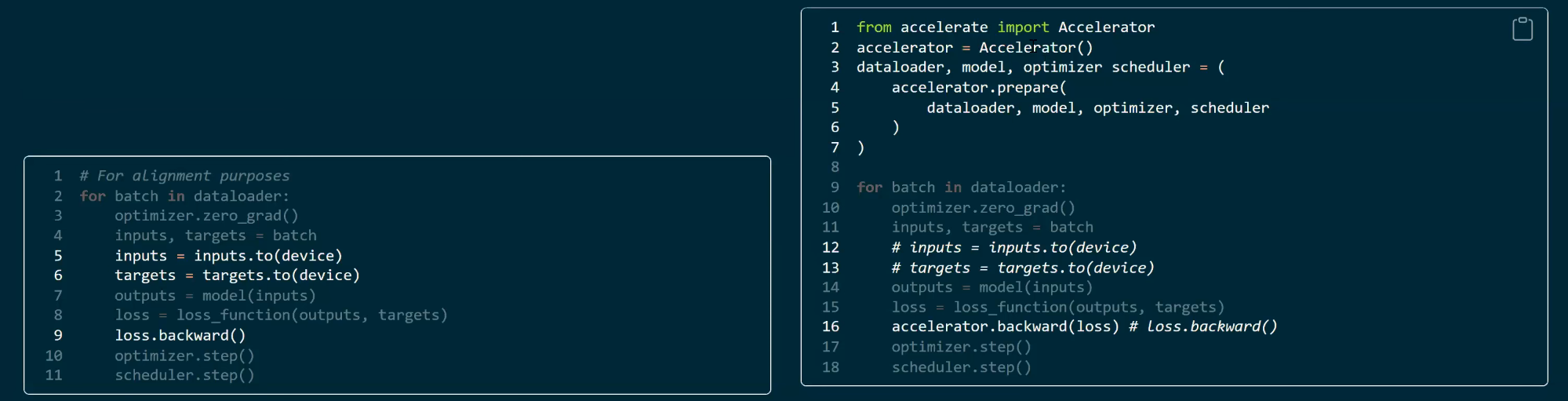
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from datasets import load_dataset
from accelerate import Accelerator #1 Import Accelerator
from torch.utils.data import DataLoader
from transformers import AdamW
from tqdm.auto import tqdm
accelerator = Accelerator() #2 Initialize the Accelerator
dataset = load_dataset(..., split='train')
model_name = ...
tokenizer = ...
model = ...
tokenized_dataset = ...
train_dataloader = ...
#3 Prepare everything with Accelerator
model, optimizer, train_dataloader = accelerator.prepare(
model,
AdamW(model.parameters(), lr=5e-5),
train_dataloader
)
#4 Training loop with accelerator.backward
model.train()
for epoch in range(1, 4):
for batch in tqdm(train_dataloader, desc=f"Epoch {epoch}"):
outputs = model(**batch)
loss = outputs.loss
accelerator.backward(loss) #4
optimizer.step()
optimizer.zero_grad()from accelerate import Accelerator
import torch
import os
accelerator = Accelerator(project_dir="my/save/path")
my_scheduler = torch.optim.lr_scheduler.StepLR(my_optimizer, step_size=1, gamma=0.99)
my_model, my_optimizer, my_training_dataloader = accelerator.prepare(my_model, my_optimizer, my_training_dataloader)
# Register the model, optimizer, and LR scheduler for checkpointing
accelerator.register_for_checkpointing(my_model)
accelerator.register_for_checkpointing(my_optimizer)
accelerator.register_for_checkpointing(my_scheduler)
# Check if a checkpoint exists and load it
checkpoint_dir = "my/save/path/checkpointing/checkpoint_0"
if os.path.exists(checkpoint_dir):
accelerator.load_state(checkpoint_dir)
print(f"Loaded checkpoint from {checkpoint_dir}")
else:
print("No checkpoint found, starting from scratch")
device = accelerator.device
my_model.to(device)
# Perform training
for epoch in range(num_epochs):
for batch in my_training_dataloader:
my_optimizer.zero_grad()
inputs, targets = batch
inputs = inputs.to(device)
targets = targets.to(device)
outputs = my_model(inputs)
loss = my_loss_function(outputs, targets)
accelerator.backward(loss)
my_optimizer.step()
my_scheduler.step()
# Save checkpoint at the end of each epoch
if accelerator.is_main_process:
accelerator.save_state()
print(f"Saved checkpoint at end of epoch {epoch + 1}")
# Save the final model
if accelerator.is_main_process:
unwrapped_model = accelerator.unwrap_model(my_model)
unwrapped_model.save_pretrained("trained_model")
tokenizer.save_pretrained("trained_model")
accelerator.wait_for_everyone()accelerate launch train.py.import argparse
import torch
from torch.utils.data import DataLoader
from datasets import load_dataset
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
get_linear_schedule_with_warmup,
AdamW,
)
from accelerate import Accelerator
from tqdm.auto import tqdm
def main():
# Parse command-line arguments
parser = argparse.ArgumentParser()
parser.add_argument("--model_name", type=str, default="gpt2", help="Model name or path")
parser.add_argument("--dataset_name", type=str, default="wikitext", help="Dataset name")
parser.add_argument("--dataset_config", type=str, default="wikitext-2-raw-v1", help="Dataset config")
parser.add_argument("--per_device_train_batch_size", type=int, default=4, help="Batch size per device")
parser.add_argument("--num_train_epochs", type=int, default=1, help="Number of training epochs")
args = parser.parse_args()
# Initialize Accelerator
accelerator = Accelerator()
device = accelerator.device
# Load the tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(args.model_name)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token # Set pad_token to eos_token if not already set
model = AutoModelForCausalLM.from_pretrained(args.model_name)
model.to(device)
# Load and preprocess the dataset
raw_datasets = load_dataset(args.dataset_name, args.dataset_config, split="train")
def tokenize_function(examples):
return tokenizer(examples["text"], truncation=True, padding="max_length", max_length=128)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True, remove_columns=["text"])
tokenized_datasets.set_format(type="torch", columns=["input_ids", "attention_mask"])
# Create DataLoader
train_dataloader = DataLoader(tokenized_datasets, shuffle=True, batch_size=args.per_device_train_batch_size)
# Prepare optimizer and scheduler
optimizer = AdamW(model.parameters(), lr=5e-5)
num_update_steps_per_epoch = len(train_dataloader)
max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
lr_scheduler = get_linear_schedule_with_warmup(
optimizer, num_warmup_steps=0, num_training_steps=max_train_steps
)
# Prepare everything with Accelerator
model, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, lr_scheduler
)
# Training loop
model.train()
progress_bar = tqdm(range(max_train_steps), disable=not accelerator.is_local_main_process)
for epoch in range(args.num_train_epochs):
for step, batch in enumerate(train_dataloader):
outputs = model(**batch, labels=batch["input_ids"])
loss = outputs.loss
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
if step % 100 == 0 and accelerator.is_local_main_process:
print(f"Epoch {epoch}, Step {step}, Loss: {loss.detach().item()}")
# Save the model (only on the main process)
if accelerator.is_main_process:
model.save_pretrained("trained_model")
tokenizer.save_pretrained("trained_model")
if __name__ == "__main__":
main()accelerate config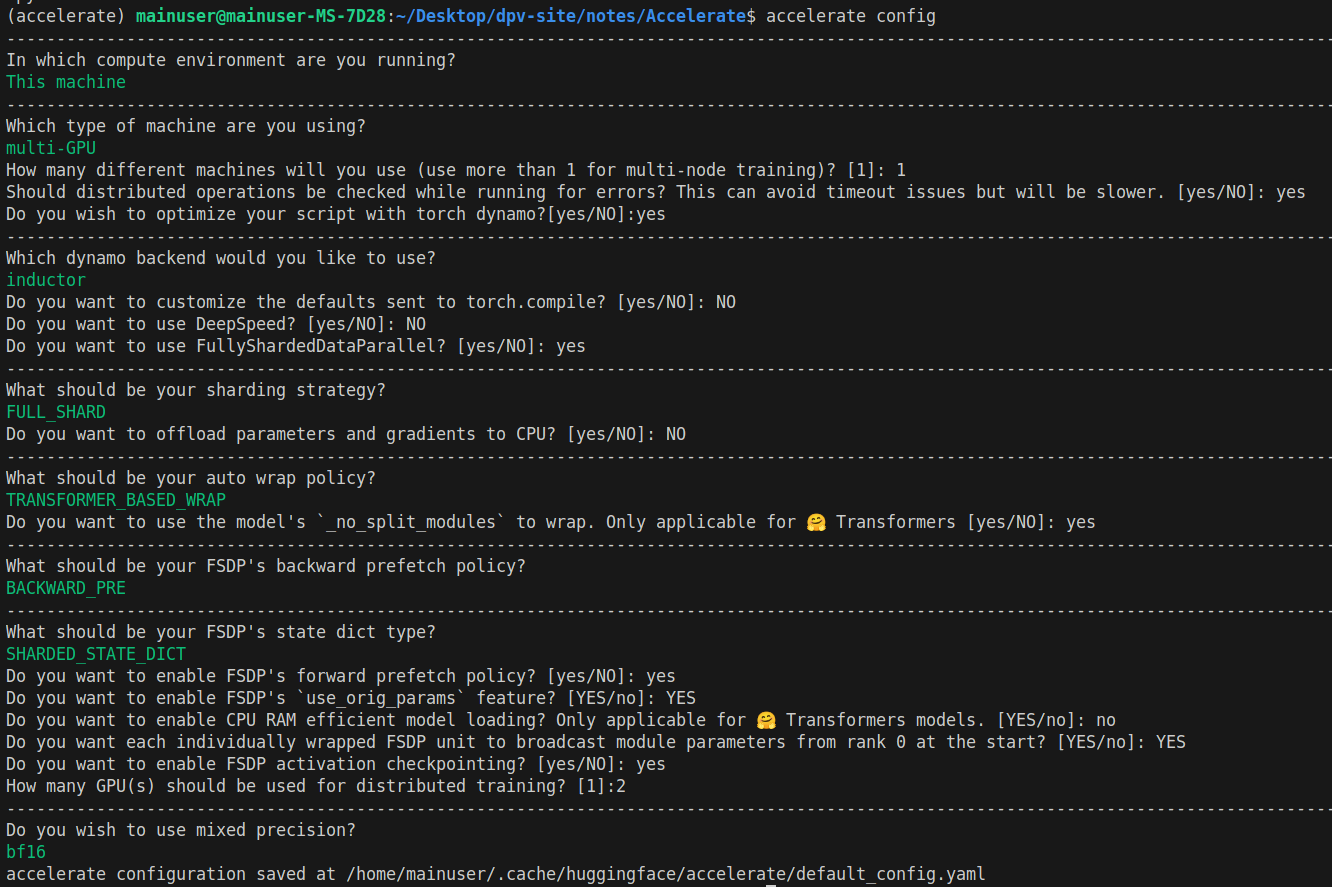
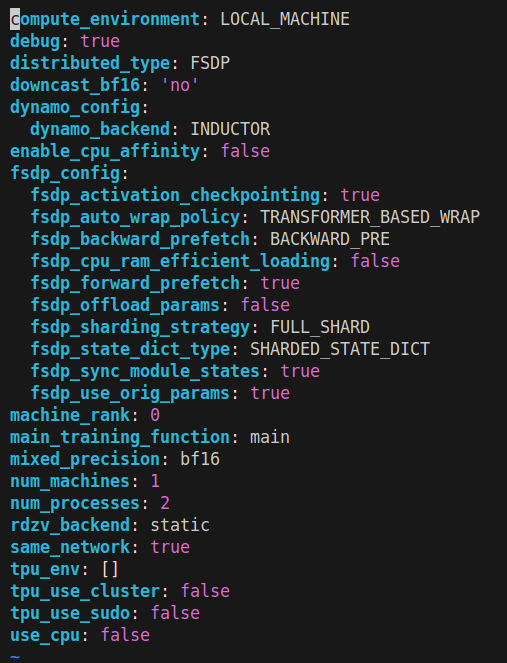
accelerate launch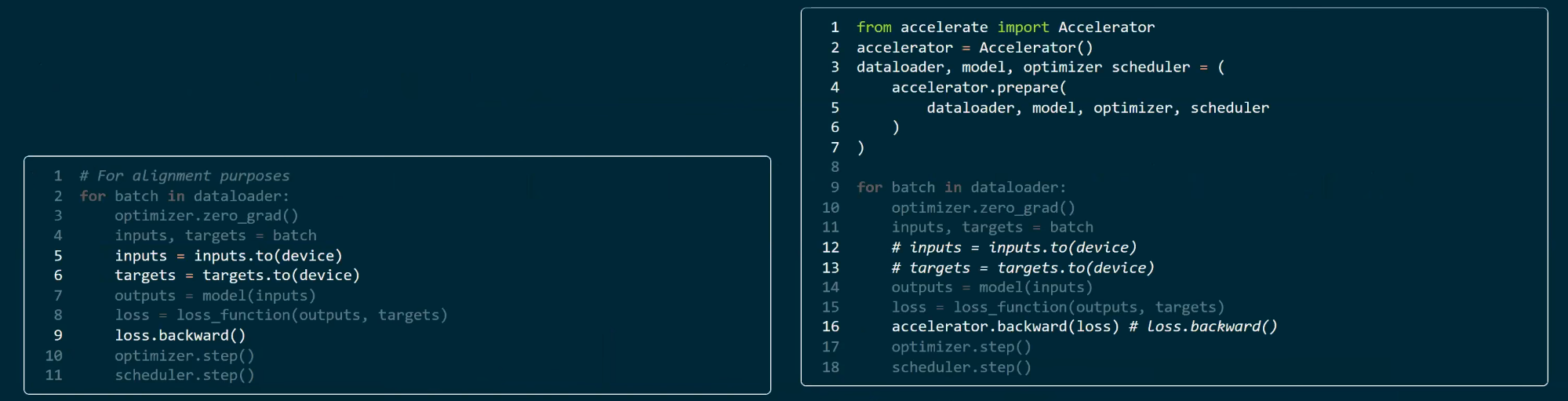
acceleratefrom accelerate import Accelerator
accelerator = Accelerator(log_with="all") # log_with='wandb'
config = {
"num_iterations": 5,
"learning_rate": 1e-2,
"loss_function": str(my_loss_function),
}
accelerator.init_trackers("example_project", config=config)
my_model, my_optimizer, my_training_dataloader = accelerate.prepare(my_model, my_optimizer, my_training_dataloader)
device = accelerator.device
my_model.to(device)
for iteration in config["num_iterations"]:
for step, batch in my_training_dataloader:
my_optimizer.zero_grad()
inputs, targets = batch
inputs = inputs.to(device)
targets = targets.to(device)
outputs = my_model(inputs)
loss = my_loss_function(outputs, targets)
accelerator.backward(loss)
my_optimizer.step()
accelerator.log({"training_loss": loss}, step=step)
accelerator.end_training()find_executable_batch_sizedef training_function(args):
accelerator = Accelerator()
+ @find_executable_batch_size(starting_batch_size=args.batch_size)
+ def inner_training_loop(batch_size):
+ nonlocal accelerator # Ensure they can be used in our context
+ accelerator.free_memory() # Free all lingering references
model = get_model()
model.to(accelerator.device)
optimizer = get_optimizer()
train_dataloader, eval_dataloader = get_dataloaders(accelerator, batch_size)
lr_scheduler = get_scheduler(
optimizer,
num_training_steps=len(train_dataloader)*num_epochs
)
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
)
train(model, optimizer, train_dataloader, lr_scheduler)
validate(model, eval_dataloader)
+ inner_training_loop()
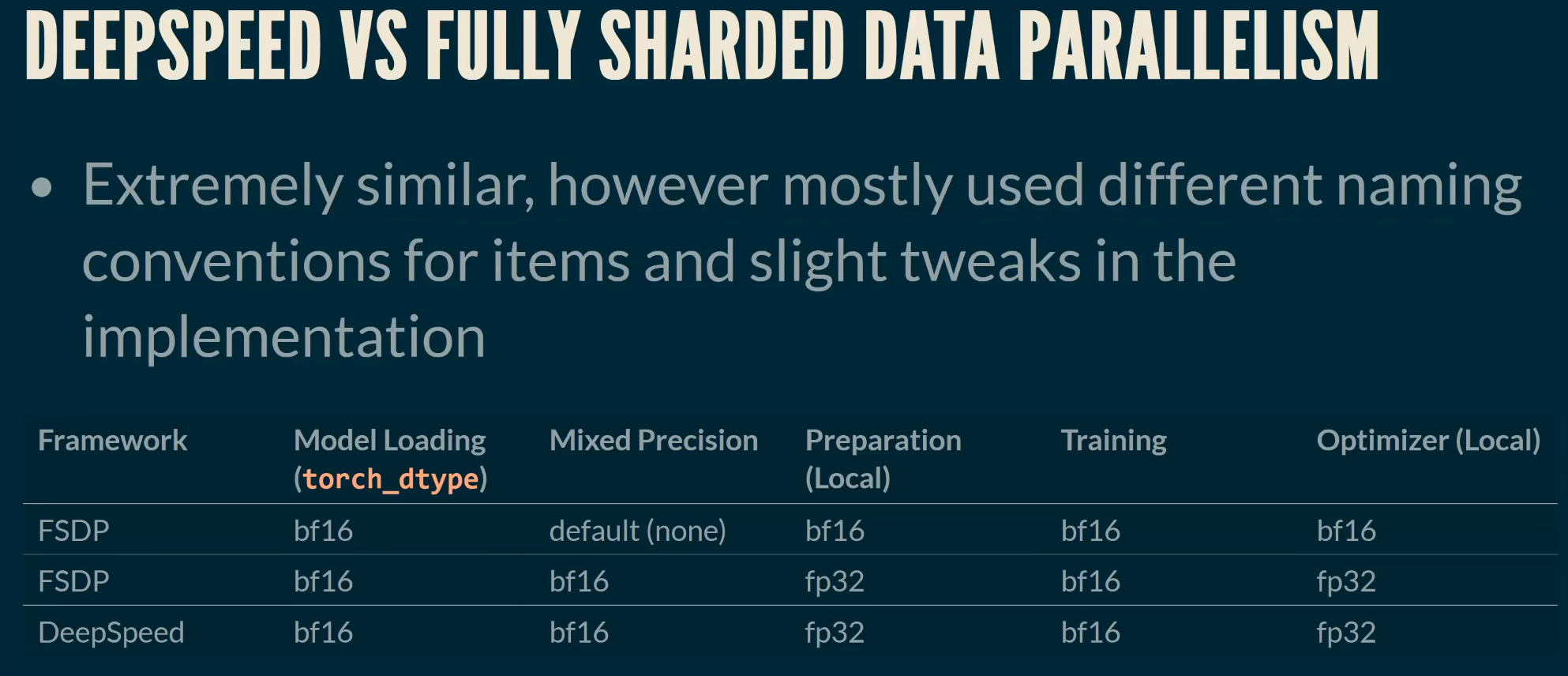
# Install necessary libraries if not already installed
# !pip install transformers datasets evaluate
import warnings
warnings.filterwarnings("ignore")
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset
from evaluate import load
# --------- 1. Load the Dataset ---------
# Using the GLUE SST-2 dataset for sentiment analysis
dataset = load_dataset("glue", "sst2")
# --------- 2. Load the Tokenizer ---------
# Using a pre-trained tokenizer compatible with the model
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
# --------- 3. Tokenize the Dataset ---------
def tokenize_function(examples):
return tokenizer(examples["sentence"], padding="max_length", truncation=True)
def sample_dataset(dataset_split, sample_size=0.05, seed=42):
"""
Samples a fraction of the dataset_split.
Args:
dataset_split (Dataset): A split of the dataset (e.g., train, validation).
sample_size (float): Fraction of the dataset to sample (e.g., 0.05 for 5%).
seed (int): Random seed for reproducibility.
Returns:
Dataset: A sampled subset of the original dataset_split.
"""
return dataset_split.train_test_split(train_size=sample_size, seed=seed)["train"]
dataset["train"] = sample_dataset(dataset["train"], sample_size=0.05, seed=42)
dataset["validation"] = sample_dataset(dataset["validation"], sample_size=0.05, seed=42)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# --------- 4. Set Format for PyTorch ---------
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
tokenized_datasets.set_format("torch", columns=["input_ids", "attention_mask", "labels"])
# --------- 5. Load the Pre-trained Model ---------
model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=2)
# --------- 6. Define Evaluation Metrics ---------
# Load multiple metrics
accuracy_metric = load("accuracy")
f1_metric = load("f1")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = torch.argmax(torch.tensor(logits), dim=-1)
accuracy = accuracy_metric.compute(references=labels, predictions=predictions)
f1 = f1_metric.compute(references=labels, predictions=predictions, average='binary')
return {
"accuracy": accuracy["accuracy"],
"f1": f1["f1"]
}
# --------- 7. Set Up Training Arguments ---------
training_args = TrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
save_strategy="epoch",
logging_strategy="epoch",
num_train_epochs=3,
per_device_train_batch_size=16,
per_device_eval_batch_size=64,
load_best_model_at_end=True,
metric_for_best_model="accuracy",
greater_is_better=True,
report_to=["none"]
)
# --------- 8. Initialize the Trainer ---------
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
# --------- 9. Train the Model ---------
trainer.train()
# --------- 10. Evaluate the Model ---------
results = trainer.evaluate()
print(results)Map: 100%|██████████| 43/43 [00:00<00:00, 6574.62 examples/s]
Some weights of BertForSequenceClassification were not initialized from the model checkpoint at bert-base-uncased and are newly initialized: ['classifier.bias', 'classifier.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.| Epoch | Training Loss | Validation Loss | Accuracy | F1 |
|---|---|---|---|---|
| 1 | 0.437700 | 0.218095 | 0.930233 | 0.938776 |
| 2 | 0.178300 | 0.144253 | 0.930233 | 0.936170 |
| 3 | 0.072500 | 0.184419 | 0.953488 | 0.958333 |
{'eval_loss': 0.1844189465045929, 'eval_accuracy': 0.9534883720930233, 'eval_f1': 0.9583333333333334, 'eval_runtime': 0.1915, 'eval_samples_per_second': 224.566, 'eval_steps_per_second': 5.222, 'epoch': 3.0}evaluate.load, make a custom compute_metrics function and pass it to the Trainer via compute-metrics argument.trainer.train(), can get results via trainer.evaluate().